페이징(Paging)
페이징이란?
- 페이징은 프로세스의 물리 주소 공간이 연속적이지 않게 하는 메모리 관리 계획법이다.
- 페이징을 통해서 외부 단편화(external framentation)을 피할 수 있다.
페이징 방법
- 물리 메모리(physical memory)를 frame이라고 하는 고정된 크기의 블록들로 나눈다.(전체 메모리를 나눈다고 보면 됨)
이 때, frame의 크기는 시스템마다 크기가 다르고, 마지막 frame에서 내부 단편화(internal fragmentation)가 발생할 수 밖에 없다.
- 논리 메모리(logical memory)를 page라고 하는 같은 크기의 블록들로 나눈다.
- CPU에 의해 만들어진 모든 주소는 두 개의 파트로 나뉜다 : page number(p)와 page offset(d)

· page number는 페이지 테이블(page table)에서의 index로 사용된다.
· 페이지 테이블은 물리 메모리에서의 각 프레임의 시작 주소를 갖고 있다.
이 시작 주소와 page offset을 결합하어 실제 물리 메모리 주소를 만들 수 있다.

- 위 그림에서 p를 이용하여 페이지 테이블에서 물리 메모리에 있는 frame의 주소를 찾은 뒤, page offset d를 더하여 실제 가리키는 주소를 찾는 것을 볼 수 있다.
해당 계산은 MMU(Memory Management Unit)이 수행한다.
ex) 32-bit CPU에서 page number로 12bit를, page offset으로 20bit를 사용한다고 하자.
이 경우 page table에서 index값의 범위는 0 ~ (2^12) - 1이 되고, frame의 크기는 2^20이 된다.
즉, page number는 페이지 테이블의 index값의 범위를 결정하고, page offset은 frame의 크기(한 번에 불러올 수 있는 block의 크기)를 결정한다.
Page offset이 작은 경우(= frame size가 작은 경우), 같은 크기의 block을 불러오는데 disk에 여러 번 접근해야 하므로 disk I/O 시간이 더 많이 걸리고, 관리해야하는 page의 개수가 늘어난다.
└> 하지만 내부 단편화가 줄어들어 메모리 낭비를 줄일 수 있게 된다.
- page의 크기는 2^n 형태로 정해진다. (보통 4KB ~ 1GB)
ex) 만약 다음 그림과 같이 논리 주소 공간이 2^m이고 page 크기가 2^n bytes라면, 논리 주소의 상위 m-n 비트는 page number가 되고, 하위 n 비트는 page offset이 된다.

ex) 32byte 물리 메모리에서 4byte page 크기를 가졌을 때 paging 예시

Paging의 overhead
- 외부 단편화가 없지만, 내부 단편화가 일부 존재한다.
- 만약 프로세스의 메모리 요구가 page 경계에 맞지 않는다면 마지막 frame은 꽉 차지 않는다.
ex) page size가 2048 bytes(page offset : 2^11 bits)이고, process가 72766 bytes를 요구한다면, 총 36페이지가 필요하므로 36개의 프레임을 할당하게 된다.
이때, 내부 단편화는 2048 - 1086(나머지 페이지는 꽉 차지만 마지막 페이지는 1086 바이트만 채워지게 됨) = 962바이트 만큼 일어나게 된다.
- page size를 크게 하면 한번에 옮겨지는 데이터의 크기가 많아지므로 disk I/O를 더 효율적으로 처리할 수 있게 되고, page size를 작게 하면 disk I/O는 비효율적이지만 내부 단편화를 줄일 수 있다.
하지만 현재의 컴퓨터 시스템에서 process와 data set, main memory가 커질수록 page size가 커지고 있다.
Hardware Support
- Page Table은 메인 메모리에 저장되어 있다.
- PTBR(page-table base register)은 각 프로세스마다 존재하고, 항상 메인 메모리에 있다.
페이지 테이블에 대한 접근은 빠르지만 user memory(실제 데이터가 저장된 곳)에 접근하는데 걸리는 시간이 중요하다.
- 위 문제를 TLB(translation look-aside buffer)라는 하드웨어 cache를 통해 해결할 수 있다.
TLB
- TLB의 각 entry는 key와 value로 이루어져있다.
- TLB는 cache처럼 사용하기 때문에 적은 page-table entry들만 가지고 있다.
· 만약 찾고 있는 page number가 TLB안에 있다면 바로 해당 page가 들어있는 frame 번호가 나오고 memory에 접근할 수 있다.(TLB hit)
· 만약 찾고 있는 page number가 없다면, page table로 접근하여 해당 page number를 찾는다.(TLB miss)
- TLB가 꽉 차게되면 대체할 entry를 골라야하는데, 고르는 방법으로는 least recently used(LRU), round-robin, random 등이 있다.
- 몇몇 TLB는 특정 entry가 제거되는 것을 허용하지 않는다.

Protection
- 각 frame에서의 데이터 보존은 protection bits를 통해 이루어진다.
- 한 비트는 페이지를 read-write나 read-only로 정할 수 있다.
- 보통 page table의 각 entry에 추가적인 비트 하나가 더 붙어서 데이터를 보존시키는데 해당 비트를 valid-invalid bit라 부른다.
· 만약 해당 비트가 valid로 설정되어있으면, 해당 페이지는 프로세스의 논리 주소 공간에 있고, 이용할 수 있는 페이지라는 것을 나타낸다.
· 만약 해당 비트가 invalid로 설정되어있으면, 해당 페이지가 프로세스의 논리 주소 공간에 없다는 것을 나타낸다.
쉽게 말해 특정 process에서 사용하지 않는 page를 구분하기 위해 사용하는 것은 valid, 사용하지 않는 것은 invalid로 나타내는 것이다.
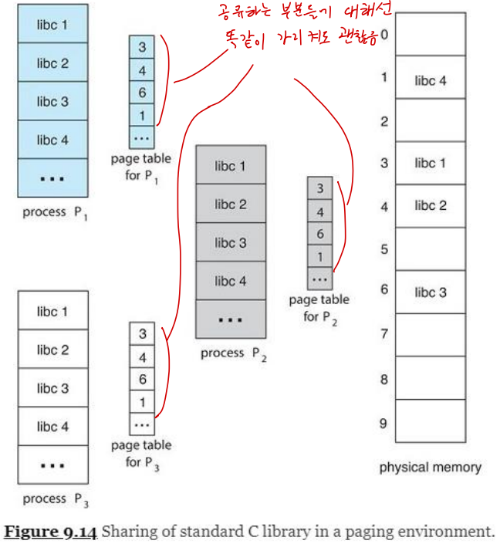
Shared pages
- 페이지의 장점으로는 동일한 코드를 공유할 수 있다는 점이다.
· 만약 어떤 코드가 나중에 다시 재진입하는 코드라면, 해당 코드는 공유될 수 있다.
※ 재진입 코드(reentrant code)는 스스로 바뀌지 않는 코드이다.
· 두 개 이상의 프로세스가 같은 코드를 같은 시간에 실행시킬 수 있다.
Hierarchical Paging
- 페이지 테이블 자체가 상당히 큰 경우가 존재한다.
ex) 32bit 논리 주소를 갖고 있는 시스템에서 page size가 4KB(2^12)라고 하자.(page offset이 12bits)
그렇게 되면 page table이 100만개 이상의 엔트리들로 이루어진다.(2^20 = 2^32 / 2^12)
만약 각 엔트리가 4byte로 이루어져있다고 가정하면, 각 프로세스는 페이지 테이블 만으로도 4MB의 물리 주소 공간이 필요하게 된다.
- 페이지 테이블을 메인 메모리에 연속적으로 할당하는 것은 효율적이지 못하므로 해결 방안이 필요한데, 가장 간단한 것으로는 페이지 테이블을 더 작은 조각들로 나누는 것이다.
Two-level paging algorithm
- 간단히 말하면 페이지 테이블을 outer와 inner로 2개를 두는 것이다.
ex) 32-bit 논리 주소 공간이 있는 시스템에서 page의 크기가 4KB라고 가정하자.

page offset이 12bits이므로 page number로는 20bit가 남게 되는데, page number를 10bit씩 나누어 각각 inner page table에 대한 page number와 page offset으로 두는 것이다.

- 64bit system으로 가게 되면 two-level이 아니라 three-level로도 존재하게 된다.
Hashed Page Tables
- 32bit 보다 큰 주소 공간을 hash를 이용하여 더 빠르고 direct하게 frame 주소에 접근하는 방식이다.
- page table의 각 entry는 3가지 요소를 갖고 있다 : virtual page number, 실제 frame의 시작 주소, 다음 element를 가리키는 포인터(collision이 일어날 경우 linked list로 관리하기 때문)

스와핑(swapping)
- 프로세스가 일시적으로 메모리에서 나와 backing storage(DISK)에 들어갔다가 다시 memory로 들어가는 방식이다.
- 스와핑의 장점으로는 물리적 메모리(실제 메모리)가 실제 크기보다 프로세스를 더 받을 수 있다는 것이다.
시스템이 실제 담을 수 있는 수보다 더 많은 프로세스들을 메모리에 담을 수 있다는 뜻이다.
· Idle process는 swap out하기 좋은 후보가 될 수 있다
· 만약 비활성화된 swap out된 프로세스가 다시 활성화되면 다시 swap in 되어야 한다.

- 리눅스, 윈도우를 포함한 대부분의 OS는 page로 swapping의 개념을 사용한다.
page를 memory에서 backing store로 옮기는 것을 page out, 그 반대를 page in이라 한다.
Demand Paging
- 프로세스의 페이지 전체를 메모리에 옮겨놓는 것이 아니라, 프로그램 실행에 필요한 페이지들만 메모리에 옮겨놓는 것을 말한다.
- 메모리에 올라간 페이지와 디스크에 있는 페이지들 간에 구분할 방법이 필요한데, 그 중 하나로는 valid-invalid bit가 있다.
(protection에서의 valid-invalid bit와 같음)
만약 이 비트가 valid로 설정되어있으면, 해당 페이지는 legal하고 메모리에 있다는 의미이다. 즉, 메모리에 있는 해당 페이지에 접근하여 정보를 변경하는 것이 가능하다는 의미이다.
하지만 이 비트가 invalid로 설정되어있으면, 이 페이지는 valid하지 않거나 valid한데 메모리가 아닌 disk와 같은 secondary storage에 있다는 의미이다.
따라서 load되지 않은 페이지에 대해서는 이 비트를 invalid로 설정하여도 상관없다.
Page fault
- 페이지 폴트란, invalid로 설정된 page에 접근을 하는 것이다. 즉, 물리적 메모리에 올라와있지 않은 페이지에 접근하는 것을 말한다.
- 페이지 폴트가 발생했을 때 해결 절차는 다음과 같다.
① 현재 프로세스가 메모리에 접근할 때, 해당 페이지가 valid한지 invalid한지 확인
② 해당 접근이 invalid하다면, OS에 trap, 즉 interrupt를 보내 이 프로세스를 멈춘다.
③ page가 backing store(disk 등)에 있는 것을 확인한다.
④ 메인 메모리에서 free frame(빈 공간)을 찾아 해당 page를 이 frame에 넣는다.
⑤ page table에서 해당 page를 valid로 초기화한다.
⑥ 멈춘 프로세스의 멈춘 부분부터 다시 시작한다.

Demand-zero memory
- Demand Paging을 수행할 때 일어나는 것으로 메모리를 할당 받았을 때, 해당 공간을 모두 0으로 초기화 시켜두는 데, 이를 demand-zero memory라 한다.
- Demand zero memory를 하지 않으면(데이터를 0으로 초기화하지 않으면)이전에 사용했던 데이터를 가져올 수 있으므로 보안 상의 문제가 발생할 수 있다.
'TIL & WIL' 카테고리의 다른 글
| [WIL] 크래프톤 정글 6주차 - Malloc Lab (0) | 2024.05.03 |
|---|---|
| [CS] 크래프톤 정글 6주차 - 이더넷(Ethernet) (0) | 2024.05.03 |
| [CS] 크래프톤 정글 6주차 - DMA(Direct Memory Access) (1) | 2024.05.01 |
| [TIL] 크래프톤 정글 5주차 CS:app 9(가상 메모리 & 동적 메모리 할당) (1) | 2024.04.26 |
| [TIL] 크래프톤 정글 5주차 CS:app 8(예외적인 제어 흐름) (0) | 2024.04.26 |



